
This short post looks at whether or not we should test our logging code. Spoiler alert: the short answer is Yes; the long answer is Yes, of course! But why, and what would it look like?
Logging originated from the act of chopping down trees for wood keeping a seafaring journal onboard a ship for navigational purposes. They tracked a ship's movement and oriented sailors to their locations. Similarly, application logs today orientate the whereabouts of the significant events that happen in your application.
Testing your logging code #
Most people agree that you test things that are important. And most people agree that logging is important. But there is a general feeling of 'yeah, it's important, but... it's just logging'.
But if we ask ourselves why we log, we get answers such as 'so that we can see what went on'. And then, if we ask ourselves 'who are we and when do we look at it?', we come to the conclusion that the audience is the support team and they look at this information when something significant happens, such as a production problem.
Support Logging #
If we think about the reason to log something as not merely adding lines of text to a file, but instead, to notify support that something significant happened, then the decision on whether it should be tested becomes easier to make.
The way I test logging, and it's something I've done since reading the excellent book Growing Object-Oriented Software, Guided by Tests (almost 10 years ago!), is to introduce a type named INotifySupport with method names relating directly to the significant things that might happen in your application:
public interface INotifySupport
{
public void ThatTheCustomerDatabaseIsDown(
[specific arguments for a broken database]);
}So your code goes from this:
var connection = ConnectToTheCustomersDatabase();
if(!connection.IsConnected)
{
_logger.LogError("Cannot connect to {DatabaseName} because {Reason}",
name,
connection.ReasonForFailure);
return;
}to this...
var connection = ConnectToTheDatabase();
if(!connection.IsConnected)
{
_notifySupport.ThatTheCustomerDatabaseIsDown(name, connection.ReasonForFailure);
return;
}The implementation of INotifySupport might merely log to a text file. At this point, you might be thinking 'Great! we've added all of this abstraction but we're doing exactly the same thing as before!' But the difference is that your application code is now much more explicit and tells the reader that you're notifying support of something significant. The person reading the code can then follow the path to see what happens when the customer database is down, or if they don't care, they can continue reading and avoid the pollution normally associated with logging. Your intent is now much more explicit.
What happens when these significant things happen?
Because we have specific methods tailored to handle specific significant events, we can now decide (in one place) what to do. We might simply log to a text file, but we now have the ability to change that behavior, and change it in just one place. For instance, the support team (the real ones, not the interface!) might ask that they receive a Nagios alert. Or we might decide to change the behavior so that we throw an exception or terminate the application.
For the latter, in C#, we can even use code analysis attributes to tell the compiler of our intent, e.g.
[DoesNotReturn]
public void ThatTheCustomerDatabaseIsDown(string reason)
{
_logger.LogError(reason);
throw new CustomerDataUnavailableException();
}... this allows tools such as ReSharper to highlight unreachable code:
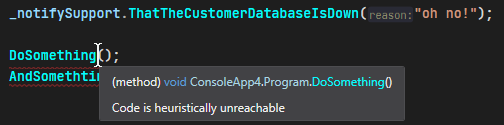
In the book Growing Object-Oriented Software, Guided by Tests, they describe logging as a feature in a section aptly named:
Logging Is a Feature
They identify that your common or garden logger has two features which share the same implementation: support logging (as above), and diagnostic logging. This shared implementation makes code more difficult to read as it pollutes the code with different concerns and also makes it more difficult to replace.
There is often a concern that INotifySupport might end up with dozens or even hundreds of methods. In reality, I've found that this hasn't happened: if your service or application is isolated and does something specific, then there shouldn't be too many significant events that the support team would need to be aware of in that area. And if there are, it could be a sign that it is doing too much. Saying that, one area that could grow is reporting on external systems that might be unavailable. For example, if your service needs to contact 10 other services to do its job, any one of those 10 other service might be down. Using the example above of NotifySupport.ThatTheCustomerDatabaseIsDown: if we had 10 other systems, it probably wouldn't be a good idea to have individual methods for each. Instead, you could notify support of a category of significant events, something like NotifySupport.ThatADownstreamSystemIsUnavailable(systemName).
Alternatively, if you did want separate methods for each, you could ExtractInterface from INotifySupport and have something like INotifySupportOfDownstreamFailures. But I generally start with a method for each system, and if it gets too much, then switch to categories. Just don't go too far with categories, because you'll end up with INotifySupport.OfAnError(string message) (aka _logger.LogError(message) !)
Diagnostic Logging #
This differs from support logging, which is the 'user interface' to your application (particularly if it's a service with nothing visible). Diagnostic logging is infrastructure for programmers; it's there to help programmers understand the system as it is being developed. It's common for diagnostic logging to be turned off in production code.
Diagnostic logging doesn't have to be inline log statements. For instance, in a debug build, you could instrument your code to trace method entry/exits with something like PostSharp.
Or, for message passing (if you're using something like MediatR), you could decorate your handlers so that infrastructure logging is isolated in the decorator. (as an aside, Simple Injector is a great Dependency Injection library that has 1st class support for decorators, but sadly, most teams stick with the vanilla .NET DI container)
What about testing? #
If you have an interface such as INotifySupport, you can now stub it and perform your tests on that.
Or, if you propagate your significant events as messages/events, you can intercept those in your tests and validate that support was actually notified.
What have we seen? #
We've seen the difference between support logging and diagnostic logging. We've seen that an abstraction over notifying significant events can simplify testing. And seeing as this abstraction lists all of the significant events in one place, we can just look at that one place to see what they are:
public interface INotifySupport
{
void ThatTheCustomerDatabaseIsDown(string reason);
void ThatTheCustomerDatabaseCameBackUp(string reason);
void ThatThereWasNoResponseFromTheAddressService(TimeSpan timeout);
void ThatWeRetriedContactingTheAddressService(AddressServiceRetryPolicy policy);
}You've got to agree that that's better than find-in-files for logger.Error(
A lot of people regard encapsulating this as over engineering ('all of that effort just to test logging!'), but it's more than logging; it's an important aspect of your system and deserves the work to make it more testable and more discoverable for the reader.
testing logging🙏🙏🙏
Since you've made it this far, sharing this article on your favorite social media network would be highly appreciated 💖! For feedback, please 🦋 ping me on Bluesky! 🦋
Leave a comment
Comments are moderated, so there may be a short delays before you see it.
Published