
The internals of the .NET Dictionary class are a common interview topic, so the information in this post might come in handy one day. You could also use this new-found knowledge to impress friends and colleagues at every opportunity!
In this post, we’ll look at the generic Dictionary<TKey, TValue> (#) type. We'll look at how values are stored and retrieved. We'll see how hash codes are handled, and we'll look at how hash code collisions are handled via a contrived example that compounds the problem.
Although having such an intimate knowledge of the internals isn't likely to be too beneficial, it is useful to know what's going on under the hood, as this knowledge can sometimes help with using things the wrong way.
Throughout this post, I refer to general dictionaries as 'a dictionary', and the .NET dictionary as 'the dictionary'. I also use the term 'entry' to represent a value, and the term 'slot' to represent an empty value.
Storing #
A dictionary is a set of key / value pairs (KVPs). But let's clarify something straight away: the .NET dictionary does not store data as KVPs.
💡Note:
It is worth clarifying this point when discussing the dictionary. Many people assume the underlying structure of the dictionary is a set of KVPs. The
KeyValuePair<TKey, TValue>type is merely one way of interacting with the dictionary; it's part of its API, but is not how things are stored internally
Data is actually stored in two arrays, one for the 'buckets', and one for the values ('entries').
The buckets link to the entries. A bucket is resolved (in part) with the value returned from GetHashCode on your key. A bucket contains your value, and, if there are any collisions, pointers to the next item in the same bucket (this is called Chaining and is explained later in this post).
To see this, we'll create our first example: a dictionary of Person / Age. Rather than use a plain string as the key, we'll use our own type to better demonstrate how the internals work:
public class Person
{
private readonly string _name;
public Person(string name) => _name = name;
public override int GetHashCode() => 1;
public override bool Equals(object? obj) =>
obj is Person p && p._name == _name;
}💡Note:
If you spotted the issue with
GetHashCodeand are now fuming and ready to scroll through cat videos on TikTok instead, calm down: the overrides toGetHashCodeandEqualsare just there to simplify the steps below.It also serves, later on, to deliberately cause hash code collisions in order to describe how they’re handled.
Now, let’s create the dictionary and add a person named Fred (Fred Flintstone):
Dictionary<Person, int> _people = new();
_people.Add(new Person(”Fred”), 42));You can step into the Add method if you’re debugging along, or you can follow the steps described below:
- the constructor checks the
capacityparameter, which defaults to0(it also defaults theIEqualityComparerparameter; this is a way to control equality if you don't own the type, but we won't be going into that in this post) - because we didn’t specify a capacity, nothing is initialised
- when we call
Add, the buckets are checked. The buckets are an array ofint. There are no buckets yet, so it initialises them. The amount of initial buckets (or capacity) is determined by getting the first prime number from a hard-coded set of the first 80 or so primes, starting at3. For a capacity of0, the prime number3is chosen, and so three buckets are created:
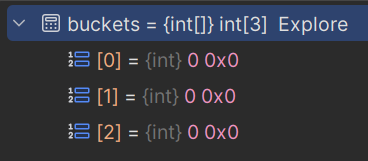
- as well as the buckets, an array of type
Entry, namedentries, is created. The array has the same size as the buckets array.Entryis a nested private struct and is described later on
Now that the buckets and entries are created, the dictionary finds out which bucket to put the person in:
- it first calls
GetHashCode()#, which is a virtual method onSystem.Object, and is the method we overrode above (note that it doesn’t directly call this method, but goes via theIEqualityComparer, but again, we won't be going into detail here) - now that it’s got the hash code, it gets the index into the bucket array. This is typically
hash code % count.
Because this is a contrived example, and we’ve overloadedGetHashCode(), we end up with a hash code of1. - now it gets a reference to the bucket at index
1(using aref int) - as seen in the screenshot above, this is0 - it subtracts 1 from this value. This is because values in the buckets are 1-based (more on why later). It is stored as a variable named
i, soi = -1 - now, it iterates through the
entriesarray starting from that index with a "while (uint)i < entries.Length" loop. Note the cast touint... - but it exits the loop immediately because
iis-1and(uint)iis4294967295(or0xFFFFFFFFin hex) (bear with me, theint/uintconversions become apparent in a bit)
As we've just seen, because this is the first item added, the loop exits immediately. If there were items, it would loop to see if it should update an existing item.
The next steps in adding an item are to do with finding out which index into the _entries array to put the value.
- it checks a field named
_freeCountto see if it's 1 or more. It's not so it sets a variable namedindexto the count of entries (0). - it sets
entries[index](entries[0]) with a new instance of theEntrytype, which contains properties:next,key,hashCode, andvalue - the reference to the bucket (in step 3) is now set to
index + 1(1) - as buckets are 1-based - it then sees if it needs to resize the dictionary. It doesn’t in this case (we have a capacity of 3, and have only populated 1 entry, but we'll be looking at sizing later on in this post)
Our buckets and entries now look like this:
We can see that the bucket at index 1 points to the entry at index 0, and the entry at index 0 is the key and value that we added. The _freeList and _freeCount fields are described shortly.
💡Note:
As described above, the bucket is typically resolved as
hash code % count. There is an optimisation called ‘fastmod’ on X64 systems which saves a long multiplication if the divisor (the length of array) is less than 2**31 (2 to the power of 31)(remember this fact; this alone should get gasps from the crowd as you explain it!)
So far, we’ve created a dictionary and added 1 item. This has resulted in 3 buckets and 3 entries, each with 1 item populated. To briefly recap; bucket #1 (relating to our hash code that we hardcoded) has a value of 1, and, since the values in buckets are 1-based, it means that it points to entry #0. The populated entry in position 0 has the value 42 which is the value we set in our code earlier. It also has a next field, which is -1 (more on this later).
Retrieving #
We've added a value to the dictionary, now let’s look at how to retrieve it:
int age = _people[new Person("Fred")];The process of finding the correct bucket is the same as we saw when adding items. You can step through the dictionary code yourself or just follow the description here. Assuming no collisions (and there aren't, yet), the flow is roughly:
- get the hash code of the key (
1) - get the value from the bucket (
1) which translates to0as it’s 1-based - get the entry from the
entriesarray at position0
At this point, ignoring collisions, we've got the value that we added earlier.
But let's not ignore collisions...
Collisions #
This post won't go into detail on hash codes and what makes a good hash code algorithm. There's a lot of information online, but just know that hash codes should be as unique as possible and, just as in real life, collisions are best avoided.
Earlier on, we deliberately set our GetHashCode() method to return 1 all the time. It’s the worlds worst hashing algorithm! We did it so that in this section, we can observe how collisions are handled.
Let’s add another person to the dictionary, Wilma (Fred's wife):
_people.Add(new Person("Wilma"), 40);Stepping through Add again, we can see a lot of similarities in the steps performed above, but there are differences:
- it calls
GetHashCode()on the key; our incredibly bad hashing algorithm returns1again - now it gets the bucket for that hash code - again
1 - now it gets a reference to the bucket at index
1- this is1- it stores this in a variable namedbucket- this is important as it will be used later - again, it subtracts 1 as the values in buckets are 1-based, and stores it as
i, soi = 0 - now, it iterates through the entries from that index (
while (uint)i < entries.Length) - this time it doesn't exit immediately - it gets the entry at
entries[i] - it compares the hash code of the person we passed (Wilma) to the person that exists (Fred). They're the same, so we have a (deliberate) collision (in a more realistic scenario, a collision is less likely, although it's still common but to a lesser extent, especially on smaller dictionaries)
- because they’re the same hash code, it also needs to compare equality. It does this by calling the virtual method
Ojbect.Equals, which we overrode and where we compare the_namefields
Up to this point, the dictionary has received an item to add, and the item has the same hash code as an existing item. And even though the hash codes are the same, the equality check is different. Because they are different, it needs to continue the loop to see if there's an existing item that needs updating...
- ... because they are not equal, it continues the loop (if they were equal, it would either overwrite the value
or throw an exception depending on theInsertionBehaviourflag) - it sets
ito the value of thenextfield of the entry; looking at the screenshot above, we can see this value is-1 - it increments a variable named
collisionCount(it also throws if the amount of collisions is greater than the amount of entries, indicating that a concurrent update has happened, rather than looping forever) - with
inow-1, it continues the loop which was started in step #5 - again, it checks the
uintvalue ofi. It is now-1which is greater than or equal to the amount of entries, so it exits the loop
It has now exited the loop and found nothing that needs updating. Because nothing needed updating, this must be a new item, so now it must find the next 'slot' in the entries to add our new person (Wilma)...
- it checks the
_freeCountvariable. There's none free, so again, it setsindexto the number of entries (1) - with an
indexof1, it setsentries[1]with a newEntryobject and populates thehashCode,next,key, andvalueproperties. Remember thebucketvariable from step #3? Thenextproperty is set tobucket - 1(so0) , which acts as a pointer to the first item in theentriesarray
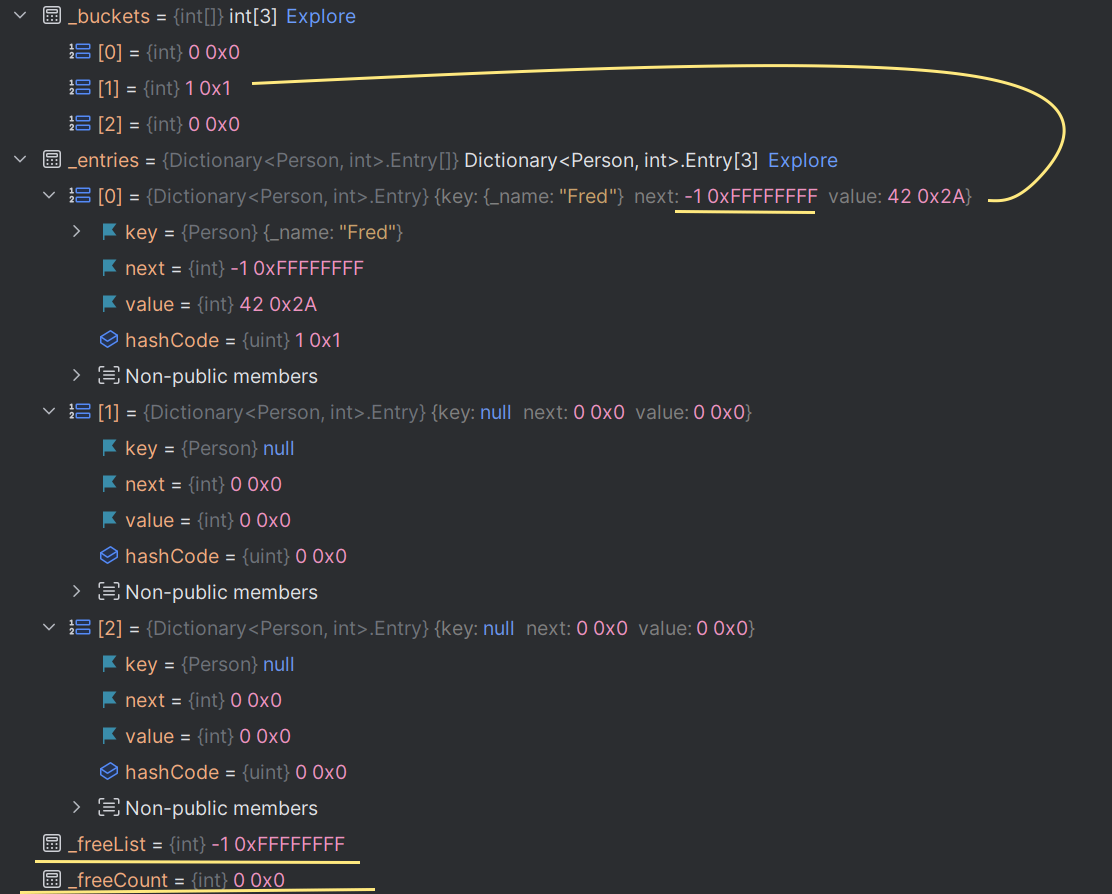
The buckets and entries now look like this:
The buckets array now says that for bucket 1, the entry is #2 (but again, it’s 1-based, so the physical position in the entries array is position #1). The _freeList and _freeCount haven't changed, but they soon will when we start removing items later on.
Position #1 (Wilma) is marked above with yellow lines, and you can see how the new item references the other item with the same hash code (Fred).
So far, we’ve created a dictionary, added 1 item, then added another item while also seeing how hash code collisions are handled.
The next thing to investigate is what happens when we get a value where the hash codes collide...
Retrieving (again) #
Here, we'll find out how the dictionary resolves values when there's a hash code collision. Let's set up our dictionary and retrieve Fred's age:
Dictionary<Person, int> _people = new();
_people.Add(new Person("Fred"), 42);
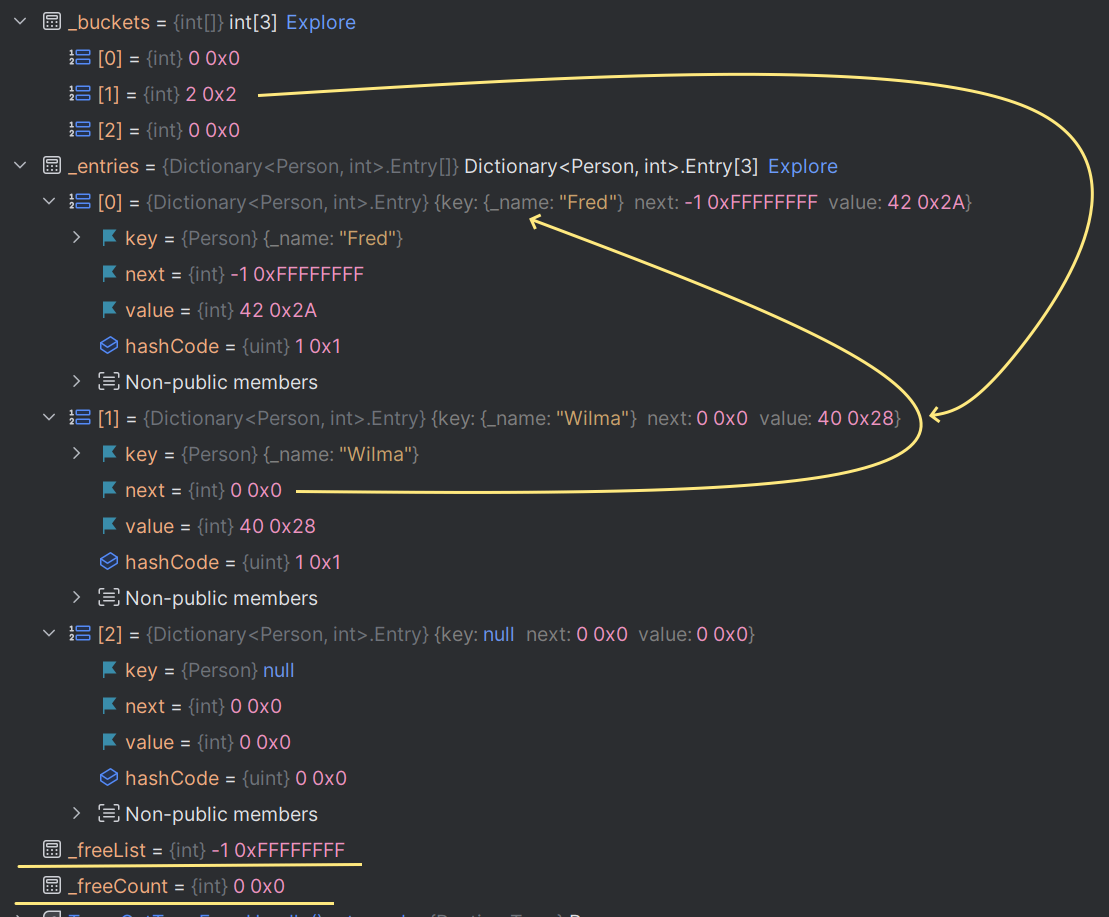
_people.Add(new Person("Wilma"), 40);The state of the dictionary at this point is the same as the immediately preceding screenshots, which should make following along easier.
Now, let's get Fred's age:
int age = _people[new Person("Fred")];To get Fred's age, these steps happen:
- it gets the hash code for the key provided (
1) - gets the value in the buckets at position
1, which is2 - it decrements this by 1 because bucket values are 1-based, and stores that in a variable named
i(soiis1) - it starts a loop - while
iis less than the number of entries (butiisn't linear in this loop) - gets the entry at
entries[i](whereiis currently1) - compares the entry’s hash code with the hash code of the provided key
- if they’re the same (and they are), then it call
Equalsto see if the provided key is the same as the stored key - if they’re the same, return the
valuein the entry, but in this case, they’re different (Fred != Wilma), so… - it sets
ito the value of thenextproperty, soibecomes0, and it increments the variable namedcollisionCount(as above, this is used to break out of the loop if the number of collisions exceeds the number of entries, indicating a changed collection and stops an infinite loop) - now, back at the start of the loop which started in step #4, we have
ias0, so, as in step 5 above, it gets the entry atentries[i](entries[0]) - compares the hash code, which is the same and compares the
Equalsmethod, which is also the same, so it breaks out of the loop - returns the value found -
42for”Fred”
Up to this point, we’ve created a dictionary, added two with colliding hash codes, and retrieved the correct item despite the collision. We’ve seen how the internal structures map from the hash code to a bucket, and from a bucket to a linked list containing the values (entries).
But what about the 1-based index of values in the buckets array?
The 1-based bucket index is an optimisation. It allows the dictionary to use the value 0 to mean an empty bucket. When all entries are removed in a bucket, the bucket isn't removed; it's just marked as empty (0)
Another optimisation in the dictionary is related to how it resolves entries where hash codes collide. A linked list is used; not a LinkedList<> itself, but by using the next property, which is an encoded index to the next item.
This is called Chaining...
Chaining #
Here's a source code comment from the next property in Entry:

Put another way:
- positive values for the
nextproperty ([0..int.MaxValue]) represent the next valid entry in a chain of used entries.-1is a sentinel value used to represent the “end of the used chain” - negative values for the
nextproperty ([-3.. int.Minvalue]) represent the next valid entry in a chain of “free entries”.-2is a sentinel value used to represent the “end of the free list”
So, what is the free chain and used chain?
The used chain links together entries in the same bucket, i.e. entries with the same hash code. That is, non-empty slots in the entries array have their next property set to the next non-empty slot.
The free chain links together free slots in the entries array. Empty slots in the entries array have their next property set to the next empty slot. This free chain helps in searching for an available slot. When entries are removed, they're not physically removed; their slots are added to the free chain for reuse, which reduces memory allocation.
Let’s see that in action. In this scenario, we’ll be starting with the dictionary above containing Fred and Wilma, and we’ll be removing “Wilma” from the dictionary:
_people.Remove(new Person("Wilma"))The code does this (in these steps, detailed descriptions for getting the hash code and bucket index are omitted for brevity)
- gets the hash code of Wilma
- gets the reference to the relevant bucket (
2) and puts it in a variable (ref int bucket) - sets variable
itobucket-1(1) - sets variable
lastto-1 - loops through the entries (
while i >= 0) and immediately finds Wilma (the entry with the same hash code and Equals), (which is index 1)
Now that it's found the exact entry to remove, it needs to tell the bucket reference that it got in step #2 to point to the next item and not this item. That's because this item is going to be 'removed' (it's not really, it's just going to be marked as free, but more on that in a bit).
Since this is the first iteration in the loop, the last variable (set in step #4) is still -1, so the check for last < 0 is matched so it sets the bucket reference (which it got in step #2) to entry.next + 1 (+1 because bucket indexes are 1-based)
If last was >= 0 (i.e. the entry that it last checked didn't match the item that we want to remove), then it would update that last entry that it iterated over by setting it's next property to this items next property, effectively making the chain skip this entry.
Up to this point, it's found the entry to be removed, and it's updated the bucket reference to tell it to point to our next item (which is Fred). If someone was to search for an item with the same hash code, Wilma would no longer be considered in the chain.
But the entry for Wilma still exists in the entries array. The entry isn't physically deleted. Instead, it's marked as part of the free chain.
This is done by setting the next property to StartOfFreeList - _freeList. Let's decipher that:
StartOfFreeListis a constant value-3- which means 'index 0 on the free list'_freeListstarts out with a value of-1(the sentinel value for ‘end of the used list’)
So next becomes -2 (-3 - -1 == -2). This means 'end of the free list'; anything that reuses this entry knows that there's not another 'next free slot'.
In finishing up the removal, it:
- sets
_freeListto the current index (1) - increments
_freeCount(to make it become1)
So, after “Wilma” has been removed, the buckets and entries look like this:
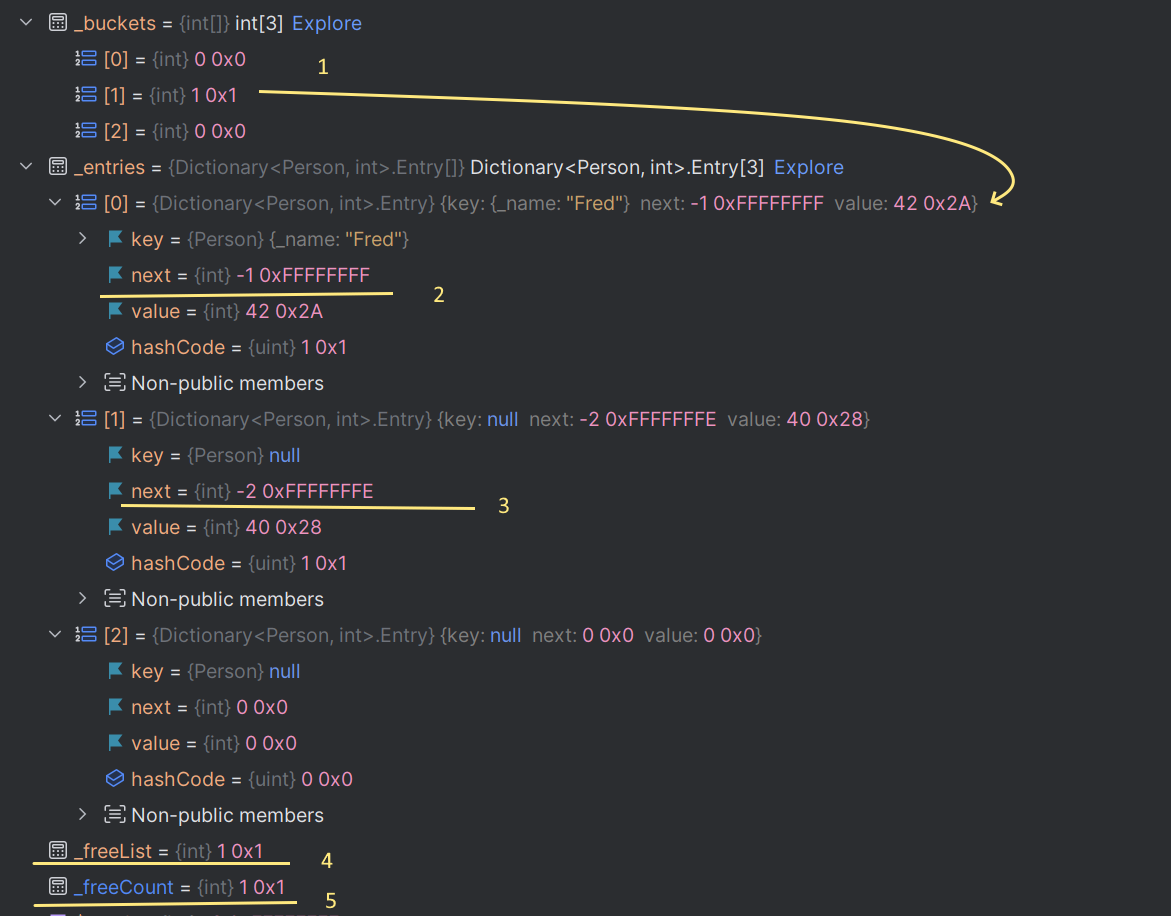
What are we looking at?
- The value in bucket 1 (captioned 1) points to entry 1 (or 0, as it’s 1-based), and this entry has a
next(captioned 2) of-1(the sentinel value for 'the end of the used chain') - the entry that previously contained “Wilma” is still there
- ... but its
nextfield (captioned 3) is-2(the sentinel value for ‘end of the free list’) _freeListpoints to entry at position 1 (where Wilma was) (captioned 4)_freeCountsays there's 1 free entry (captioned 5)
As dry as this topic is, we should cover how _freeList and _freeCount are used. To do this, we'll:
- create a dictionary with 4 entries, again with Fred and Wilma, but now with Barney and Pebbles (Fred's neighbour and daughter!)
- remove 2 entries
- add 1 entry—to see where it gets the next available entry
We’ll look at the state after each of those operations to examine and understand the next field and _free* fields.
Create a dictionary with 4 residents from the Bedrock community:
Dictionary<Person, int> _people = new();
_people.Add(new Person("Fred"), 42);
_people.Add(new Person("Wilma"), 40);
_people.Add(new Person("Barney"), 30);
_people.Add(new Person("Pebbles"), 3);The dictionary internals now look like this:
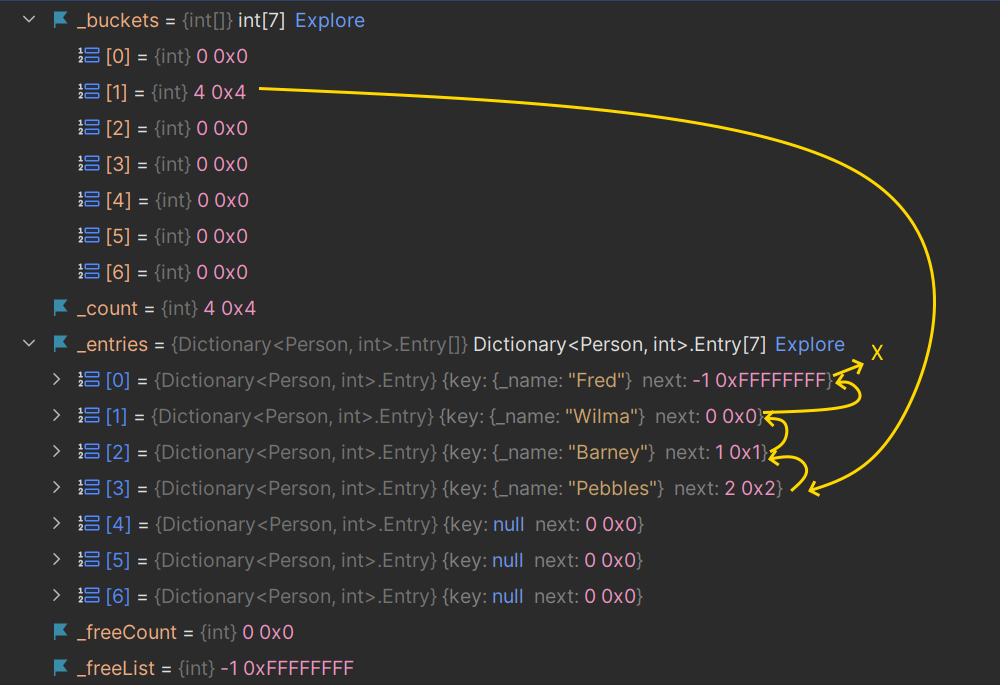
This is hopefully a familiar picture as we've seen something similar previously: bucket 1 points to the 3rd entry. This entry points to the 2nd entry, the 2nd entry points to the 1st entry, and the 1st entry points to the 'end of the used chain'.
The _freeList field points to -1 (the end of the used list)
Now, let’s remove Wilma:
_people.Remove(new Person("Wilma"));The dictionary now looks like this:
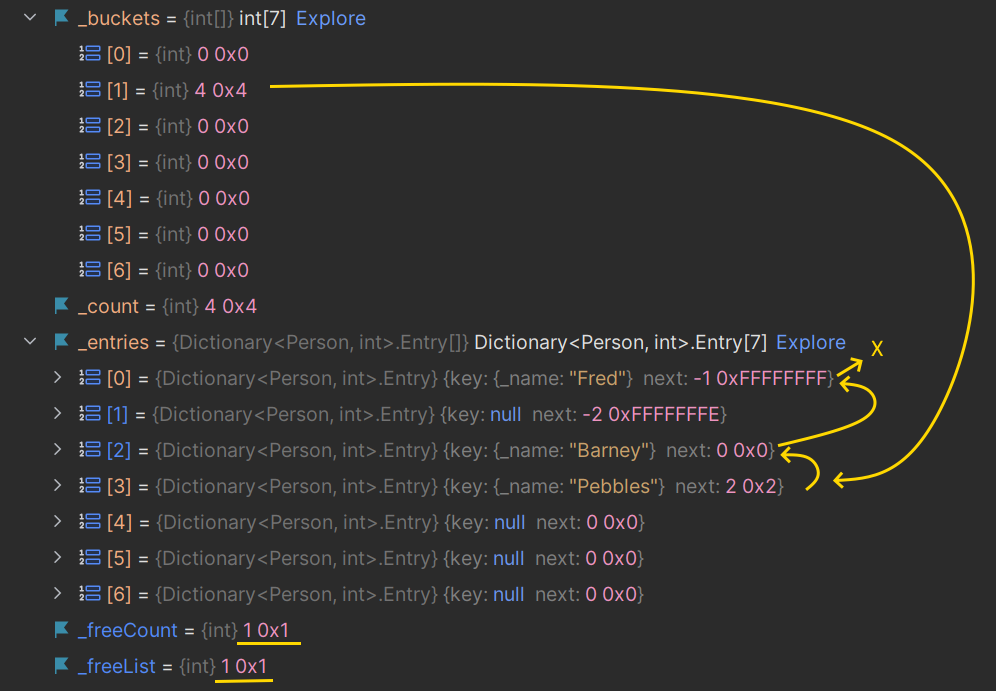
We can see that the place where Wilma was is now empty and has a next of -2, signifying ‘end of the free list’.
We can see that _freeCount is 1, and _freeList (the next free position) is 1 where Wilma used to be.
Now, remove Pebbles:
_people.Remove(new Person("Pebbles"));After removing Pebbles:
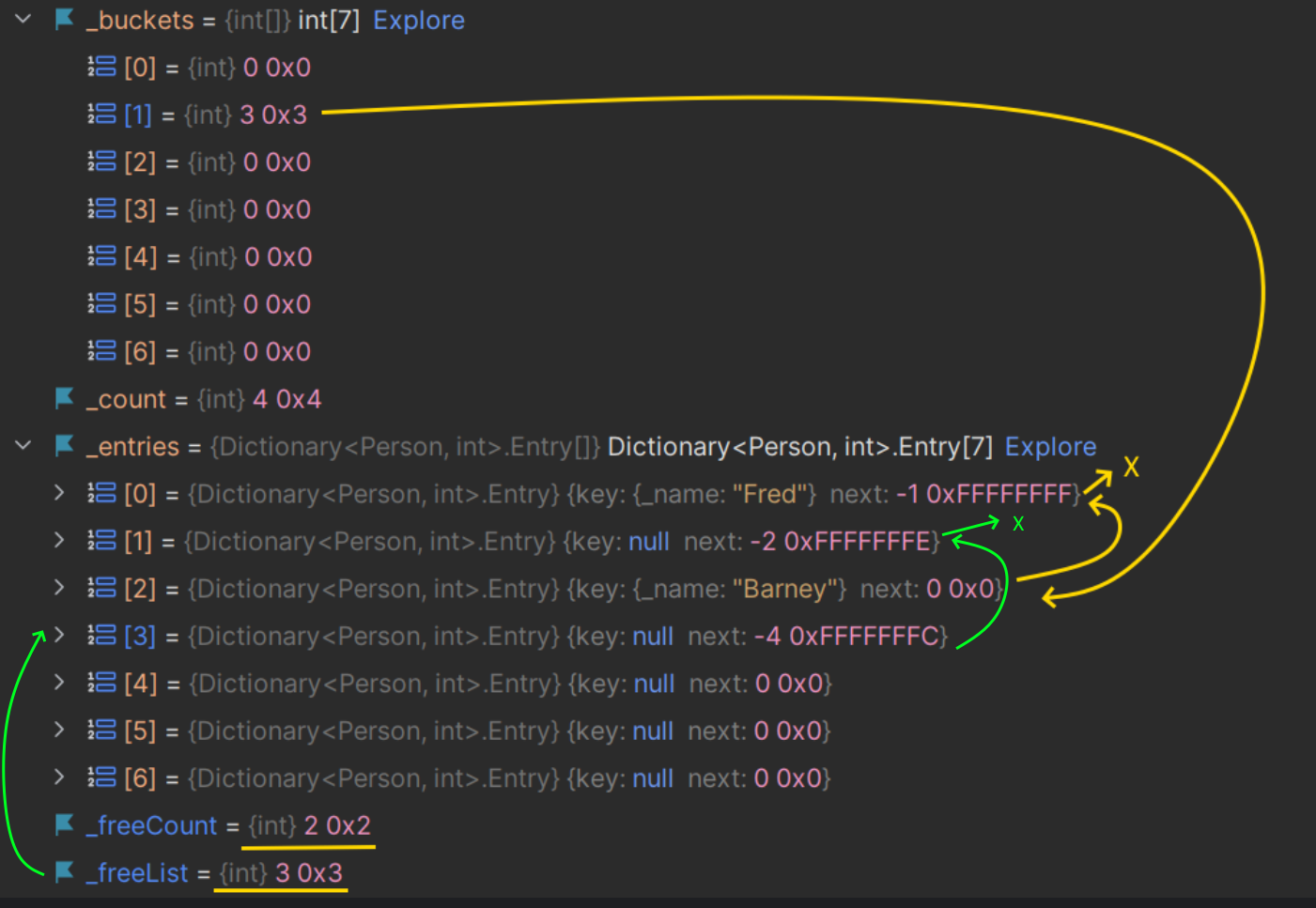
What are we seeing?
Let's start with the yellow lines:
- bucket 1 points to entry 2
- entry 2 points to entry 0
- entry 0 points nowhere (
-1means "end of the chain") _freeCountsays there are two free items_freeListsays that the first free item is at slot 3
The green lines say:
_freeListpoints to slot 3- slot 3 (where Pebbles used to be) is now empty and has a
nextvalue of-4, signifying "Index 1 on the free list" (remember code comment fornext: "... changing sign and subtracting 3") - so,-4becomes4, and4-3is1. - slot 1 is empty and has a next of
-2(meaning the end of the free list)
We've now got a dictionary with free entries where we've deleted items. You can see that the dictionary hasn't shrunk; the places that used to contain values are empty and marked as free using the encoding in the next property.
Now, as the very last stop, let’s see how these empty entries are recycled by adding a new entry to the dictionary.
Let's now add “Bamm-Bamm” (Barney’s daughter!)
_people.Add(new Person("Bamm-Bamm"), 3);Here's the new state of the dictionary:
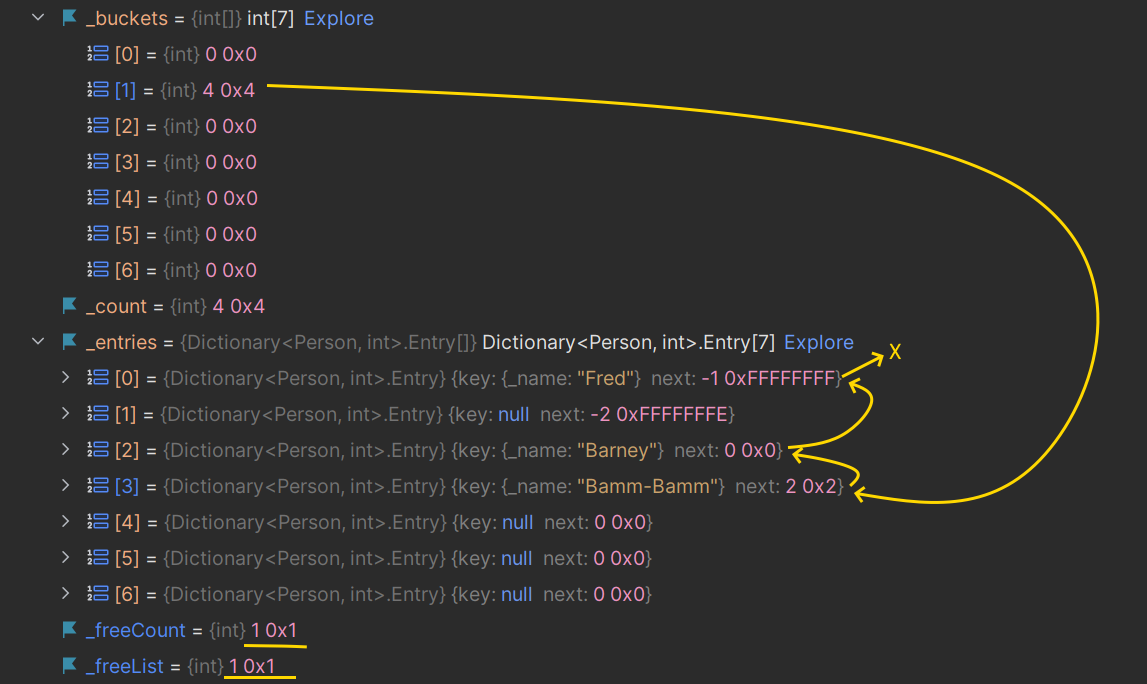
What this shows is:
- it reused the slot in
entriesthat used to contain Pebbles; it knew to use this slot (slot 3) because that was the value in_freeList - before overwriting this new slot, it took the
nextproperty, which was-4, which means 'index 1 on free list' (remember from the comments, 'change sign and subtract 3') - so it sets
_freeListto be1, which is the index to the next free item - the next free item, which is index
1has anextof-2(the sentinel value for the “end of the free list”) - it has decremented
_freeCount
Our dictionary has been through a few changes: we've added 4 items, removed 2, and added 1. it's current state is that there's one free slot (_freeCount=1), and it's at position 1 (_freeList=1). The entry at slot 1
You'll be relieved to hear that that's the end of stepping through the internals of how collisions are handled!
The takeaway from all of the above is that a bad hashing algorithm causes lots of additional work. So a good hash code algorithm will solve everything!... Not quite:
Better hash codes mean no collisions... 🤔 #
Let's change the code at the start of this post. Delete GetHashCode from Person:
public class Person
{
private readonly string _name;
public Person(string name) => _name = name;
🗑️➤ public override int GetHashCode() => 1;
public override bool Equals(object? obj) =>
obj is Person p && p._name == _name;
}Now run this again, with our usual four Bedrock residents:
Dictionary<Person, int> _people = new();
_people.Add(new Person("Fred"), 42);
_people.Add(new Person("Wilma"), 40);
_people.Add(new Person("Barney"), 30);
_people.Add(new Person("Pebbles"), 3);
… and observe the output—there’s still a hash code collision as we can see below (there are 4 people but only 3 buckets):
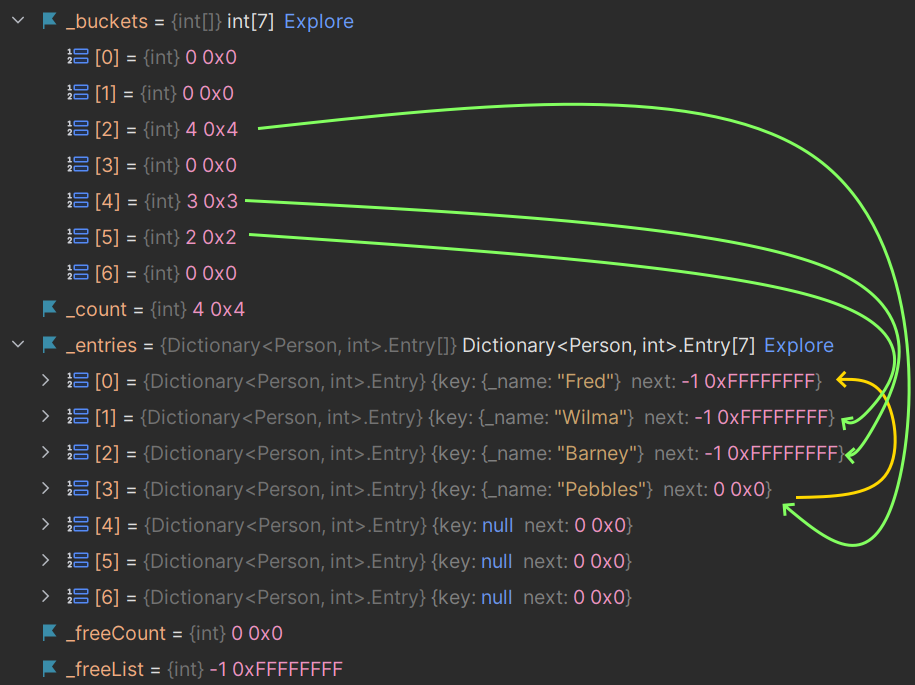
There are only 3 entries in _buckets, and the entry for Pebbles is linked to Fred!
Technically, this is a ‘bucket collision’ rather than a ‘hash code collision’: the hash code from Fred and Pebbles are different (your values may differ as they're based on memory addresses):
Person fred = new("Fred");
fred.GetHashCode()
2606490 0x27C59A
Person pebbles = new("Pebbles")
pebbles.GetHashCode()
23458411 0x165F26B…but, remember, the bucket is determined by the hash code modulo the size of the entries:
fred.GetHashCode() % 7
4 0x4
pebbles.GetHashCode() % 7
💥 4 0x4(again, your values may differ, and you may not get a bucket collision here, but the principal is the same)
What’s the impact of this on performance?
The impact is negligible. Collisions are fewer the bigger the dictionary is. So it might be worth considering allocating a dictionary bigger than what you need. As an aside, most collections allow you to specify an initial capacity; specifying this can increase performance and reduce memory allocations due to eliminating ‘sparse arrays’.
Resizing #
As we’ve seen, the capacity of a dictionary is different from the number of items added. We’ve seen above that the first item added to a dictionary sets the capacity to 3. 3 is the lowest prime number that the dictionary uses. When more items are added, the capacity is increased.
We can see this in action by creating a dictionary and adding 4 items. The first item added sets the capacity to 3. When adding the last item, we'll exceed the capacity and cause a resize:
Dictionary<Person, int> _people = new();
_people.Add(new Person("Fred"), 42);
_people.Add(new Person("Wilma"), 40);
_people.Add(new Person("Barney"), 30);
_people.Add(new Person("Pebbles"), 3);When the dictionary added Pebbles, it checked a variable named _freeCount. This was 0 because there were no free slots. So a resize happened.
The first thing that happens in the Resize method is a call to HashHelpers.ExpandPrime(_count, false) - count is 3 and the false represents forceNewHashCodes.
ExpandPrime first sets newSize to 2 * oldSize
It then checks the new size (6) to see if it’s bigger than the maximum prime array length. This is declared as:
// This is the maximum prime smaller than Array.MaxLength.
public const int MaxPrimeArrayLength = 0x7FFFFFC3;This is 4 bytes less than Array.MaxLength (0x7FFFFFC7) and is 60 bytes less than Int32.MaxValue (0x7FFFFFFF).
If the new size is greater than the max size (and the max size is greater than the old size), then capacity is reached and capacity isn’t increased. Otherwise, it gets the prime number for the new size. So the new size is 6, which the dictionary uses to loop through the hardcoded primes to find the first one that is larger or equal to.
So, the first iteration of the loop of primes (3, 7, 11, 17, 23... ) yields 3. The next iteration yields 7, which is >= the new size of 6. So that is chosen as the new ‘capacity’ of the array (remember, we were only adding the 4th item at this point).
Now that it has a new prime number representing the new capacity, it’s time to physically resize the dictionary. First, it creates a new array of entries with that capacity, and then copies the old array into it.
Remember earlier there was a bool flag to specify whether new hash codes were needed? In this case, it’s false, so nothing happens in that regard (interestingly, keys that are value types never have their hash codes recalculated, presumably because only reference types are ever moved around in memory when the array is copied, meaning that a new hash code is needed because the default GetHashCode relates to the object's location in memory).
Next, a new buckets array is created. It iterates the entries array and…
- if the entry at position
ihas anextthat is>= -1, then it gets a reference to an int in the buckets array based on that entry’s hash code (hashCode % buckets.Length). It sets the entry’snexttobucket -1(buckets are 1-based), and sets the entry in the_bucketsarray toi + 1
So, after the resize (but before Pebbles is actually added), the only change is the capacity of the arrays:

🤓 Note:
To summarise: when an item is added and there’s no room for it, the capacity is doubled and then rounded up to the nearest prime number.
Downsizing #
Dictionaries are ever expanding (at least in the current implementation). They don't get smaller when items are removed. One question I had when delving into the source code of the dictionary was: if _freeList points to the next free item, why does it need the _freeCount variable? After all, when nothing is ‘free’, then _freeList is -1.
The answer to that question is:
The internal count differs from the external count. The internal count is the count of the entries, including ‘free’ entries. The external count is the count of used entries.
This is visible from an earlier screenshot where we added 4 items and removed 2 items, but the internal count (_count) was still 4:
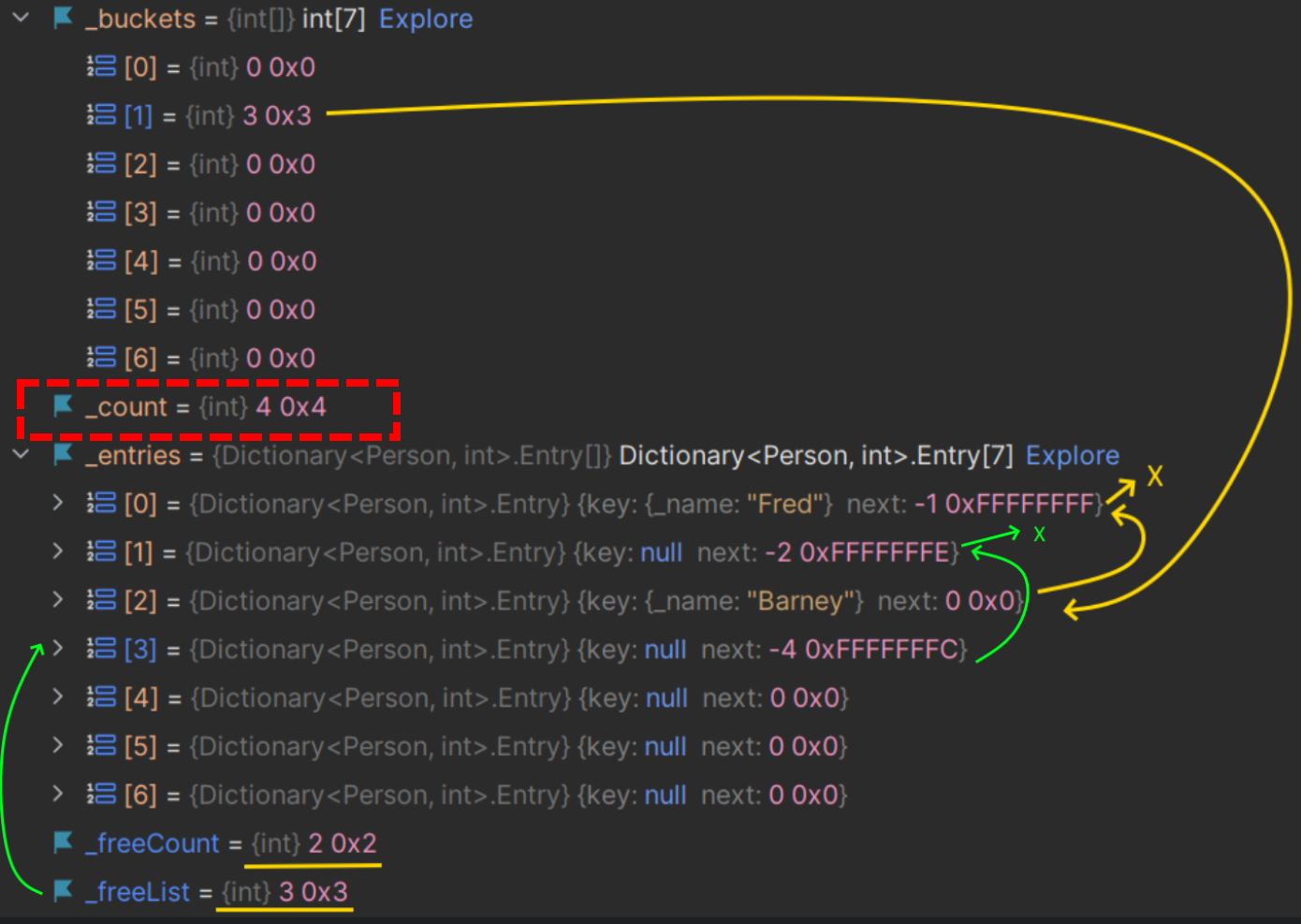
You can see _count is 4 even though we'd removed 2 items. The Count property (the public property not shown on the screenshots) would return 2 here. The source code for this property matches this behaviour:
public int Count => _count - _freeCount;To free up memory, use the TrimExcess method:
🤓 TIP
If you need to free up memory, for instance, on a large dictionary that has had a lot of churn, then
you can use theTrimExcessmethod
What about KeyValuePairs? #
As we approach the end of this painfully dry blog post, It would be remiss not to mention KeyValuePairs (KVPs).
KVPs are the ‘interface’ to a dictionary. The internal storage doesn’t use them. They’re used to get data into the dictionary and can be used to get data out of the dictionary. Let’s see that. This is how to get items in:
KeyValuePair<Person, int>[] items =
[
new(new Person("Fred"), 42),
new(new Person("Wilma"), 40),
new(new Person("Barney"), 30)
];
Dictionary<Person, int> _people = new(items);This is how to get items out:
foreach (KeyValuePair<Person,int> eachPair in _people)
{
...
}When the dictionary's constructor takes KVPs, it takes the key and value and adds them as if you directly called Add(key, value). Each KVP is not stored anywhere in the dictionary.
Similarly, when getting KVPs out of the dictionary, e.g. via foreach, the enumerator enumerates the _entries array and converts those into KVPs.
What have we seen? #
We've seen just how dry and boring a blog post can be. Mind you, it's only boring to most people in most situations. It seems incredibly interesting in some situations; for instance, an interviewer requiring a candidate to have an unhealthy intimacy with the internals of the dictionary.
csharp dotnet anatomy collections🙏🙏🙏
Since you've made it this far, sharing this article on your favorite social media network would be highly appreciated 💖! For feedback, please 🦋 ping me on Bluesky! 🦋
Leave a comment
Comments are moderated, so there may be a short delays before you see it.
Published
2 comments on this page
Thanks @MortenStov - to provide your own hash, you can use the overload that takes an
IEqualityComparer. Also, I think the most optimal capacity is the one that's implemented, which is is the next prime number that is larger than the entries that you have (or expect).I would guess that the fastest way to initialise a dictionary would be to read your data into
KeyValuePairs, and then use the constructor that takes those.Morten Stov
This was a fantastic blog - thanks.
What I really would like to see in the class is:
And some questions:
a) I have an ulong key and could provide a better GetHascode() function. Is that possible?
b) is there a faster collection when I only do inserts and lookups?
c) is there a "fastest" way to initialize a Dictionary from say a file (Deserialize)
d) Is there a guideline to optimal initial capacity such as 2 or 4 times expected number of entries?